智谱 GLM-4.6V
Cherry Studio 用户现在可以通过内置的 CherryIN 服务免费体验 智谱 GLM-4.6V——由 Z.ai(智谱 AI)于 2025 年 12 月发布的视觉旗舰模型,MoE 架构、128K 原生多模态上下文、原生多模态工具调用,是图文理解与多模态 Agent 场景的首选。
🚀 什么是 GLM-4.6V?
GLM-4.6V 是 Z.ai GLM-V 系列的最新一代视觉语言模型,原生支持文本 + 图像统一建模,在 GLM-4.5V 的基础上进一步扩展上下文与工具调用能力。
- 架构:Mixture-of-Experts(MoE)
- 总参数量:106B
- 激活参数量:约 12B
- 上下文长度:128K tokens
- 开源许可:MIT
- 发布时间:2025 年 12 月 8–9 日
- 视觉编码器:支持多分辨率图像(最高 4K)
系列同时包含 GLM-4.6V-Flash(9B),面向本地与低延迟场景,免费可商用。
📚 延续 GLM-V 系列的多模态训练体系
GLM-4.6V 沿用了 GLM-4.1V-Thinking / GLM-4.5V 的技术路线,并在视觉与 Agent 方向做了进一步强化:
- 原生多模态建模:文本与图像联合训练,支持图文混合输入
- 上下文扩展:训练上下文扩展至 128K tokens,单次可处理约 150 页密集文档、200 页幻灯片或 1 小时视频
- 原生多模态工具调用:工具可以直接接收与返回图像,基于扩展的 MCP 协议以 URL 方式处理多模态产物
- 强化学习增强:沿用 GLM-V 系列的可扩展 RL 流程
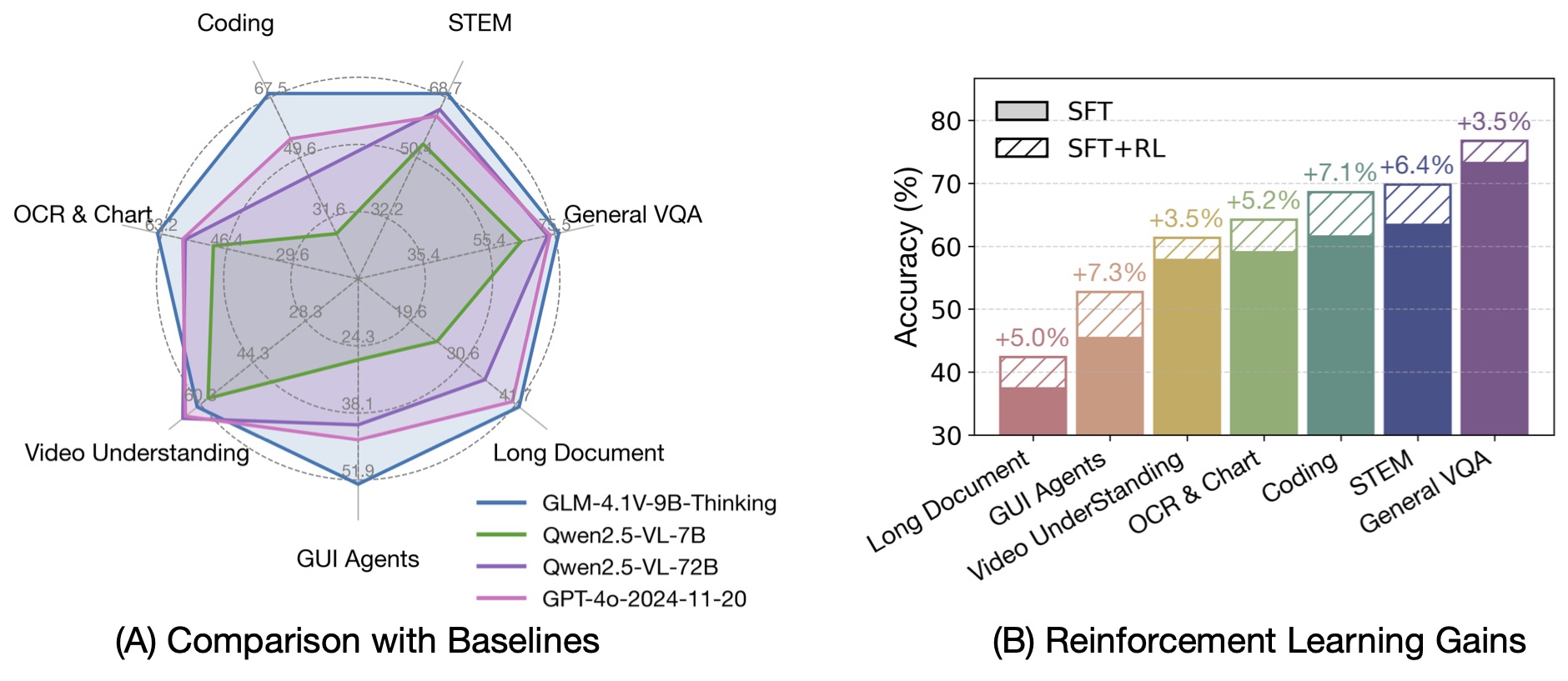
⚙️ 原生多模态,面向真实场景
GLM-4.6V 的多模态能力覆盖日常与专业场景:
- ✅ 富文本内容理解:长文档、多页文本与图文混排
- ✅ 视觉网页搜索:结合视觉输入进行联网检索与理解
- ✅ 前端复刻:从设计稿或 UI 截图生成前端代码
- ✅ 长上下文多模态文档分析:整份 PDF / 幻灯片 / 视频级输入
- ✅ 图表与表格解析:结构化信息抽取
💡 原生多模态工具调用与 Agent 能力
GLM-4.6V 的核心升级之一,是 "视觉感知 → 可执行动作" 的闭环:工具调用原生支持图像作为输入与输出,让多模态 Agent 在真实业务中落地。
| 场景 | 推荐用法 | 示例 |
|---|---|---|
| 简单图文问答 | 直接对话 | "这张图里有什么?" |
| 中等复杂任务 | 启用工具调用 | 读取图表后检索数据 |
| 复杂多模态 Agent | 多工具 + MCP | 截图 → 理解 → 调用 API → 生成报告 |
🌟 高效 MoE,开放可用
- ⚡ MoE 稀疏激活:106B 总参数,仅激活约 12B
- 💰 通过 CherryIN 在 Cherry Studio 中免费使用
- 🖥️ 权重、推理代码与 MCP 工具已在 GitHub 与 Hugging Face 开源,MIT 许可
🧠 聚焦实用能力:多模态助手
GLM-4.6V 在实际使用中适合以下场景:
- 文档助手:长文档、扫描件、幻灯片整份阅读与摘要
- 数据分析:识别并解读图表、仪表盘截图
- 前端与设计:根据 UI 截图生成或修改前端代码
- 视觉搜索:结合图像进行联网检索与信息整合
- 多模态 Agent:结合浏览器、代码执行、检索等工具完成复杂任务
🧭 如何在 Cherry Studio 中使用?
- 打开 Cherry Studio,进入 设置 → 模型服务。
- 找到 CherryIN 服务商并开启。
- 在模型列表中选择 智谱 GLM-4.6V。
- 返回聊天界面,在顶部模型选择处切换为 GLM-4.6V,即可在对话中直接上传图片进行图文交互。
💡 提示:CherryIN 提供的免费模型额度由 Cherry Studio 官方承担,适合日常体验与评测;生产环境建议结合 Z.ai(智谱)官方 API 使用。
📘 立即体验 智谱 GLM-4.6V,解锁原生多模态与视觉 Agent 能力!